МФЖ-101. Современные технологии поиска и обработки информации. Практическое задание №4. Sentiment-анализ
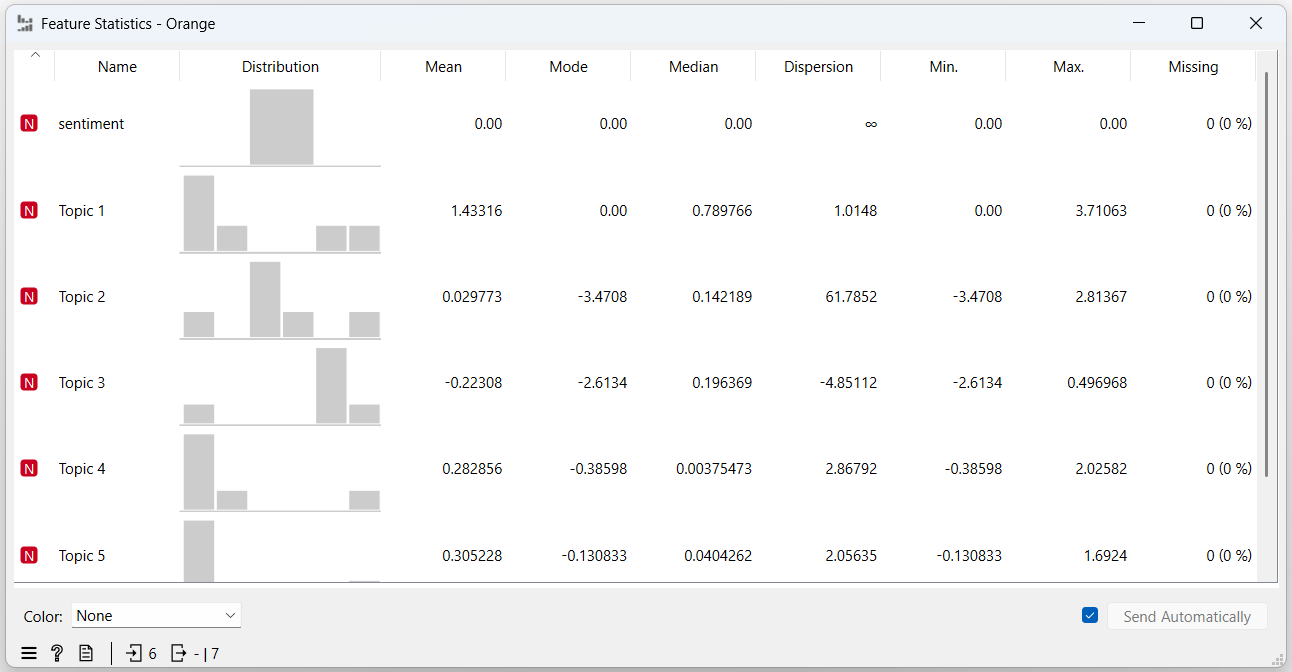
Вам нужно проанализировать на эмоциональную составляющую любые два текста достаточного объема с использованием моделей MDS и Feature Statistics.
Для этого подготовьте каждый из текстов отдельно. Откройте Microsoft Excel и расставьте весь текст поабзацно в строки первой колонки, затем сохраните его в формате CSV. Можно также использовать Google таблицы: https://docs.google.com/spreadsheets/u/0/. Для сохранения файла используйте путь: файл - скачать - формат csv.
1) Формируете форк по схеме:
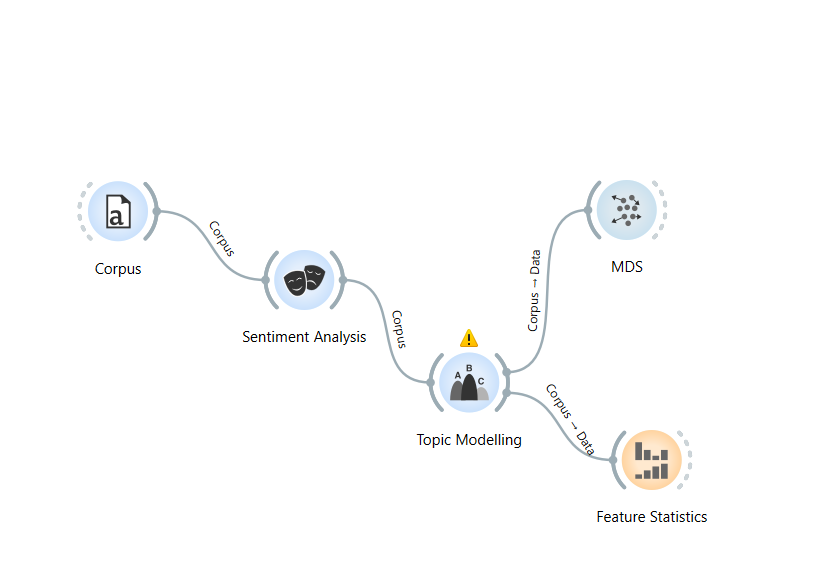
2) В компоненте Corpus указываете путь к вашему первому текстовому csv файлу;
3) В компоненте Sentiment Analysis выбираете мультиязычный компонент и устанавливаете русский язык;

Ссылки на выполненное в вашем блоге задание принимаются в комментарии к данному посту до 17:00 четверга, 16 апреля.
Ссылку на страницу можно получить, выбрав опцию просмотра (иконка "глаз") в настройках публикации.

https://gormost.blogspot.com/2026/04/101-4.html?m=1
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://www.blogger.com/blog/post/edit/6082448773569325343/537953391809551752
ОтветитьУдалитьОценка "отлично"
Удалить