МФЖ-101. Современные технологии поиска и обработки информации. Практическое задание №2. Автоматизированный кластерный анализ
Подготовьте данные для анализа, выбрав от 6 до 10 текстов на схожую тему и сохраните их в виде .txt файлов (типа блокнот) в общей папке.
1) Формируете форк по схеме:
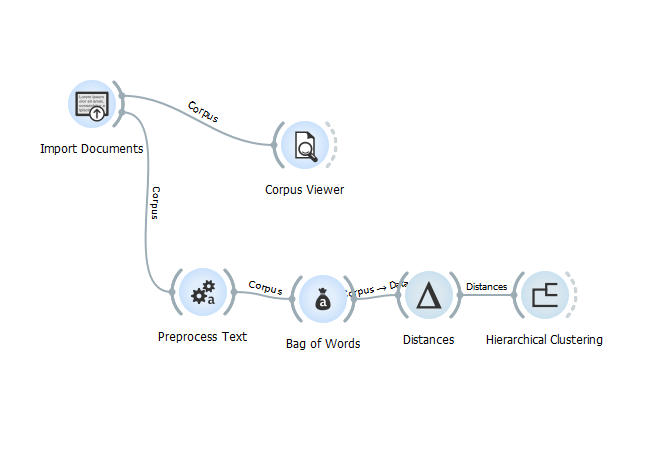 Описание анализа: верхний уровень - проверка отображения данных, нижний - непосредственная процедура анализа.
Описание анализа: верхний уровень - проверка отображения данных, нижний - непосредственная процедура анализа.Управление в Orange: правая клавиша мыши открывает меню. Начните набирать текст для поиска инструмента. Левая клавиша мыши используется для выбора виджетов. Для соединения виджетов в единый форк (цепь) зажмите левую клавишу мыши и ведите линию вправо к следующему виджету. Все виджеты открываются кликом по их иконке.
Анализ:
2) Откройте Import Documents и укажите путь к папке, в которой лежат все ваши тексты;
3) Подключите виджет к corpus viewer чтобы увидеть источники;
4) Соедините виджет с Preprocess Text и выберите параметр Regexp;
5) Соедините Preprocess Text с Bag of Words. Regularization установите со значением Euclidean;
6) Выберите Distances и затем Cosine metric;
7) Присоедините виджет Hierarchical Clustering в конце форка;
8) Откройте кластер и выберите следующие группы параметров: linkage - ward, annotation - name, после чего передвиньте вертикальный разделитель (пунктир) так, чтобы тексты разбились по группам кластеров, согласно их логике.

Описание результата: сделайте скриншот с разделением массива текста на кластеры. Кратко опишите тексты какой тематики вы использовали? Поясните на какие группы разделились выбранные вами тексты и дайте обоснование почему именно такие группы были выделены?
Ссылки на выполненное в вашем блоге задание принимаются в комментарии к данному посту до 17:00 четверга, 19 марта.
Ссылку на страницу можно получить, выбрав опцию просмотра (иконка "глаз") в настройках публикации.
https://gormost.blogspot.com/2026/03/101-2.html
ОтветитьУдалитьОценка "отлично"
Удалить