ЖМК-301/2. Методика медиаисследований. Практическое занятие №4. Автоматизированный фоносемантический и контент-анализ
Для данного задания потребуются любые два текста на общую тематику (укажите, что за тексты вы рассматривали) достаточного объема, сохраненные отдельно в формате .txt в две разные папки.
Предустановленное ПО: Vaal Mini (для фоносемантического анализа) и Orange Biolab Si с плагинами: Orange3-text, Orange3-textable, Orange3-timeseries и Orange3-ImageAnalytics (контент-анализ).
При выполнении задания укажите какие тексты вы рассматривали.
Часть 1: Фоносемантический анализ.
1) Запустите программу Vaal.
2) Укажите путь к первому тексту: файл - открыть - ваш файл
3) Далее в верхнем меню: анализ - эмоциональная оценка текста
4) Сохраняете результаты и проделываете то же самое со вторым текстом
5) Сравниваете ваши тексты и делаете вывод о том, чем они отличаются с точки зрения эмоционального посыла. Аргументируйте. Используйте скриншоты с результатами в качестве иллюстраций.
Часть 2: Контент-анализ.
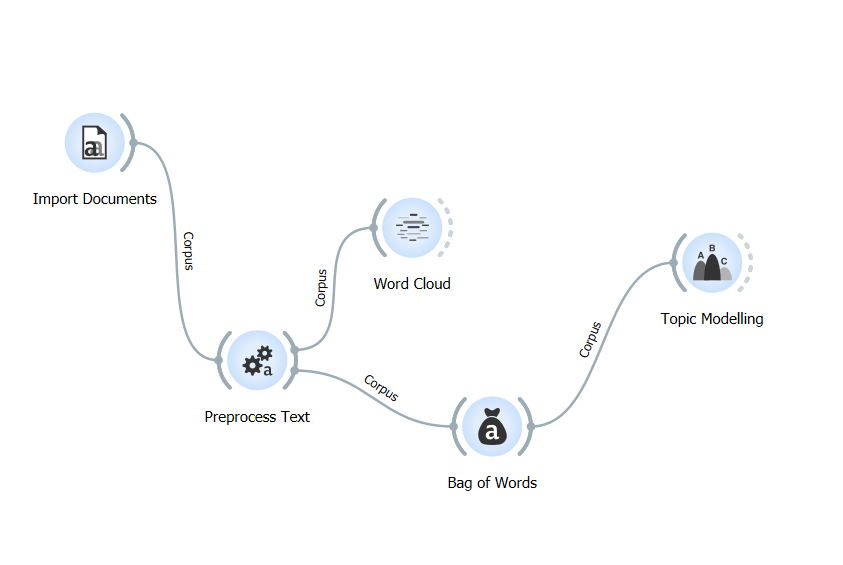
Ссылки на выполненное в вашем блоге задание принимаются в комментарии к данному посту до 17:00 понедельника, 3 ноября.
РЕЗУЛЬТАТЫ:
Акимкина Олеся - 5
Ананина Виктория - 5
Андрюк Анастасия - 5
Власов Максим - 5
Гайфуллина Анна - 5
Гостева Полина - 5
Григорьева Екатерина - 5
Дашенко Александра - 5
Кобякова Дарья - 5
Козилова Елизавета - 5
Корнилова Полина - 5
Куликова Мария - 5
Мамонтова Мария - 5
Маханек Вера - 5
Митюнин Андрей - 5
Новая Валентина - 5
Орлова Арина - 5
Слободская Елизавета - 5
Султанова Ирина - 5
Фомин Александр - 5
Хайруддинов Тимур - 5
Цветкова Виктория - 5
Чубаков Константин - нет первой части
Чугунова Елизавета - 5
Шабалина Виктория - 5
Шестакова Вероника - 5
Широкоумова Полина - 5
Щербакова Ангелина - нет первой части
https://darkzet76.blogspot.com/2025/10/blog-post_31.html
ОтветитьУдалитьhttps://vikki0s.blogspot.com/2025/10/301-1-1.html
ОтветитьУдалитьhttps://dashnko.blogspot.com/2025/10/blog-post_31.html
ОтветитьУдалитьhttps://besheniff.blogspot.com/2025/11/blog-post.html?m=1
ОтветитьУдалитьhttps://dariakobykova.blogspot.com/2025/11/10.html
ОтветитьУдалитьhttps://slobodskayal.blogspot.com/2025/10/blog-post_31.html
ОтветитьУдалитьhttps://akimkinaolesia.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьhttps://irinkasul.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьЧугунова Елизавета https://kedamo.blogspot.com/2025/11/302-4.html
ОтветитьУдалитьhttps://kulikovamariaa22.blogspot.com/2025/11/4.html
ОтветитьУдалитьhttps://marywow.blogspot.com/2025/11/3012-4.html Мамонтова Мария
ОтветитьУдалитьhttps://mediaeconomicsananina.blogspot.com/2025/11/4.html
ОтветитьУдалитьhttps://ekozil.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьhttps://mityunindesign.blogspot.com/2025/11/4.html
ОтветитьУдалитьhttps://philosopherarishka.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьhttps://cityhistory12.blogspot.com/2025/11/1.html
ОтветитьУдалитьhttps://ssshivvva.blogspot.com/2025/11/302.html?m=1
ОтветитьУдалитьhttps://iamnovaia.blogspot.com/2025/11/4.html
ОтветитьУдалитьКорнилова Полина https://polypropyleneeeee.blogspot.com/2025/11/302-4.html
ОтветитьУдалитьhttps://kontrv.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьШирокоумова Полина https://sirokoumovapolina.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьhttps://shestakovanika8518.blogspot.com/2025/11/4.html
ОтветитьУдалитьЧубаков Константин
ОтветитьУдалитьhttps://chhkss.blogspot.com/2025/11/blog-post.html
https://fomin11.blogspot.com/2025/11/1-2.html
ОтветитьУдалитьhttps://nasnrk.blogspot.com/2025/11/blog-post.html
ОтветитьУдалитьhttps://polinagost.blogspot.com/2025/11/blog-post.html?m=1
ОтветитьУдалитьГайфуллина Анна:
ОтветитьУдалитьhttps://praltikakonoplyova.blogspot.com/2025/11/4.html