ЖМК-301. Методика медиаисследований. Практическое занятие №2. Кластерный анализ из внешней базы данных
Подготовка:
1. Добавьте виджет Guardian, нажмите на API key, затем ок. Укажите на английском ключевые слова запроса и диапазон времени (берите небольшой, чтобы анализировать не более 15-25 файлов, иначе анализ займет очень много времени),выберите блок headline и content, нажмите search:
Внимание! Виджет анализирует англоязычную газету Guardian, поэтому ключевое слово/слова запроса должны быть также английскими.
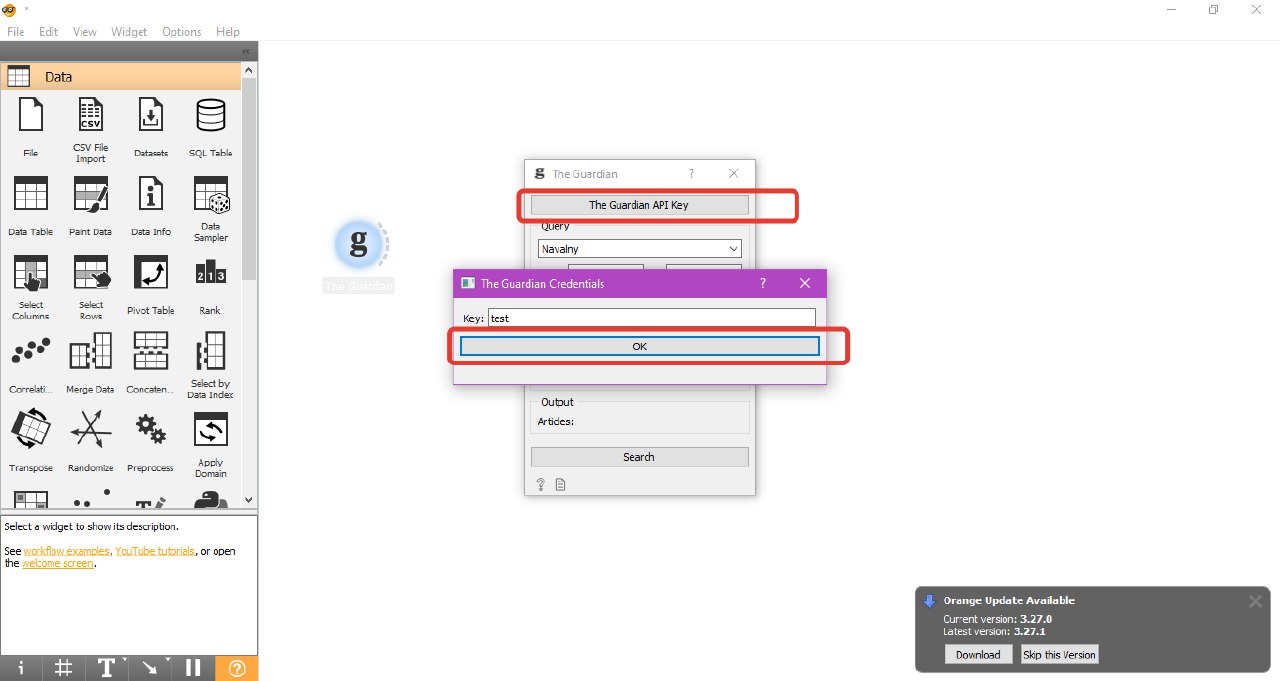
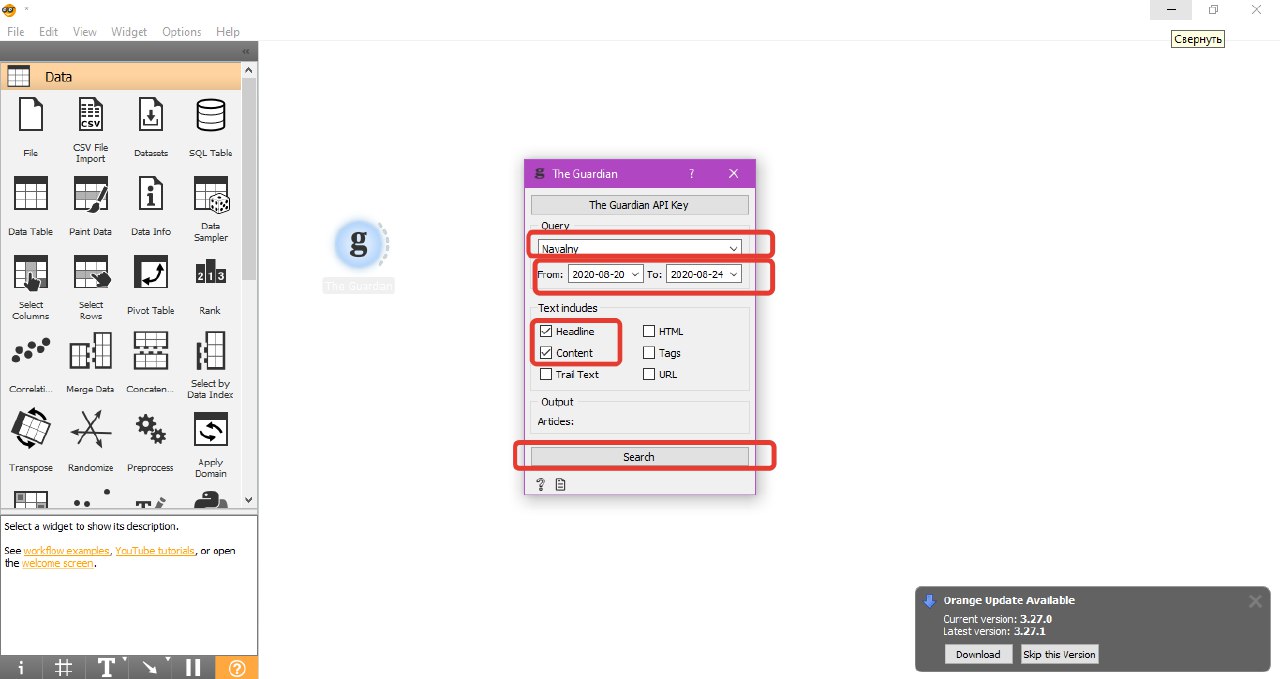
Схема анализа:
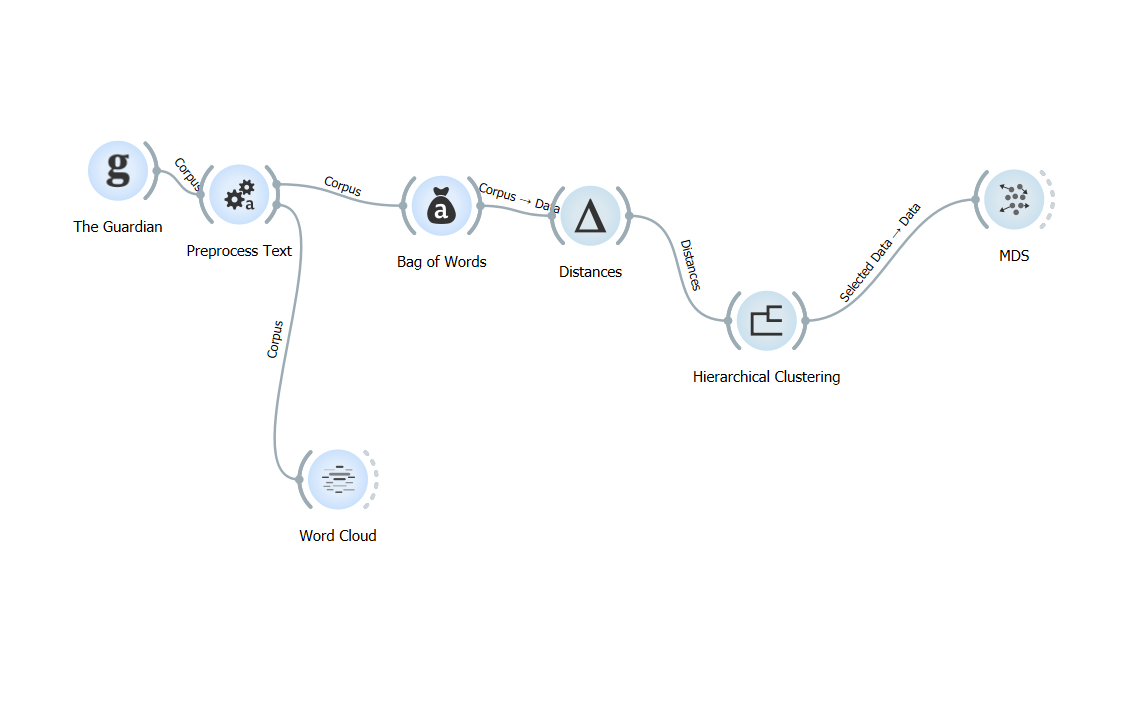
Подключение и настройка виджетов проводится также как и в предыдущем задании.
Анализ:
3. Откройте Preprocess Text и установите значения: Lowercase, Regexp, Stopwords.
4. Соедините виджет с Word Cloud чтобы увидеть частотность слов.
5. Соедините Preprocess Text с Bag of Words с параметрами: count, none, eucledian.
6. Соедините Bag of Words с Distances, укажите параметр rows type. Regularization выставляется с параметром Euclidean.
7. Соедините Distances с Hierarchiacal Clustering с параметрами linkage - word content и annotation - content.
8. Подключите в конце форка MDS модель.
9. В ней выставите в цвете - секцию, в форме - кластер, в размере - слово, а в лейбле - заголовок. Нажмите на кнопку PCA и затем на старт. Перед вами карта полей кластеров и их связей.

10. Сохраните итоговый вариант как картинку и опубликуйте отдельным постом в блоге, аргументированно объяснив как:
а) связаны тексты с совпадающими цветными полями - что их на ваш взгляд объединяет?
б) связаны тексты, с общими линиями пересечений.
Приведите по 1-2 примера на пункты а) и б)
Ссылки на выполненное задание принимаются в комментариях к данному посту до 15:00 10 марта
https://merzlyakovaaa.blogspot.com/2023/03/2.html
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://lidiasaleikina.blogspot.com/2023/03/8.html
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://normchel.blogspot.com/2023/03/blog-post.html
ОтветитьУдалитьОценка "отлично"
Удалить