Современные технологии поиска и обработки информации. МЖФ-101. Практическое задание №5. Простой sentiment анализ
1. Выберите любой англоязычный текст из СМИ достаточного объема и оформите его в CSV-файл. Для этого откройте google таблицы: https://docs.google.com/spreadsheets/u/0/ и расставьте весь текст поабзацно в строки первой колонки, после чего сохраните в нужном формате (файл - скачать - формат csv);
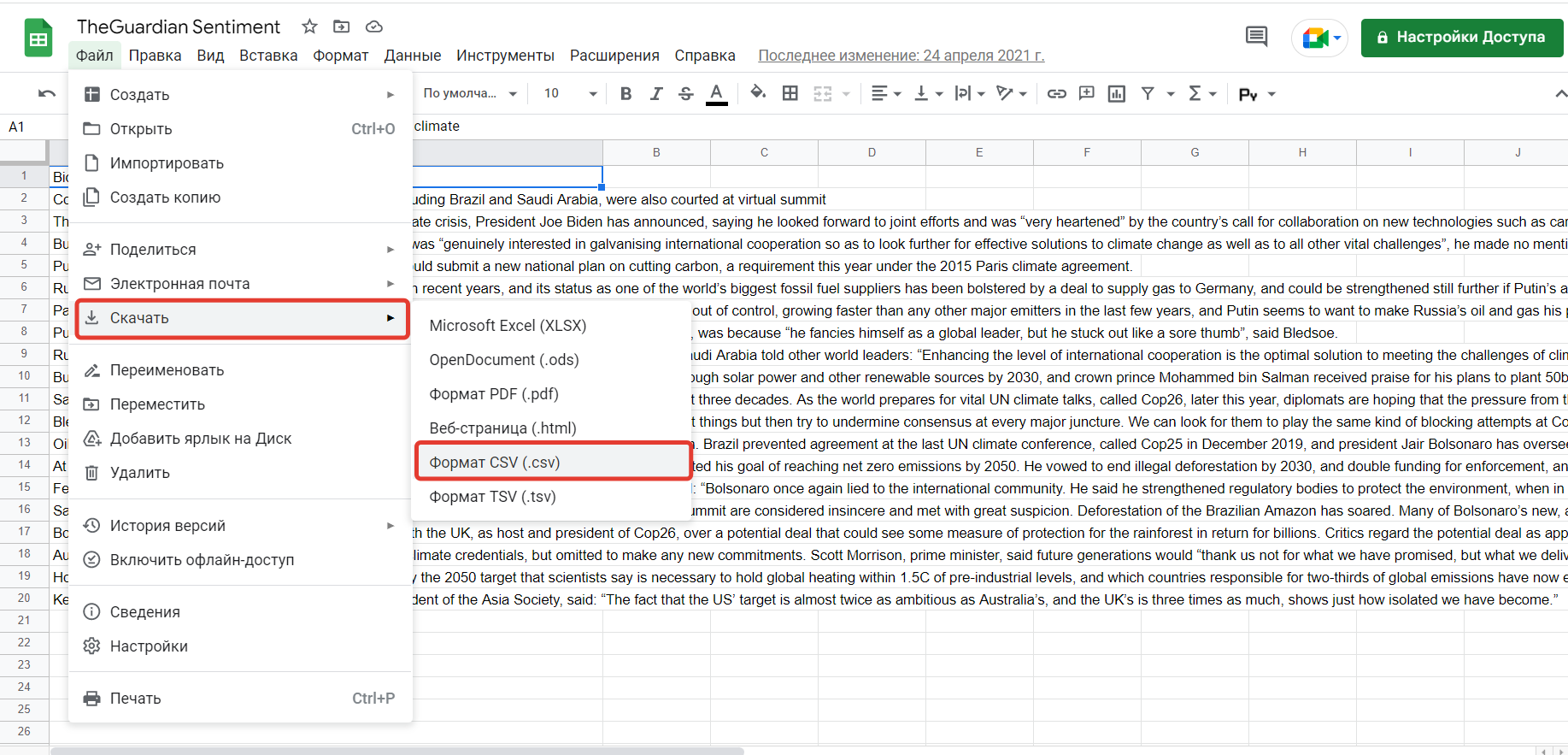
2. Запустите в Orange инструмент Corpus и загрузите в него ваш файл;
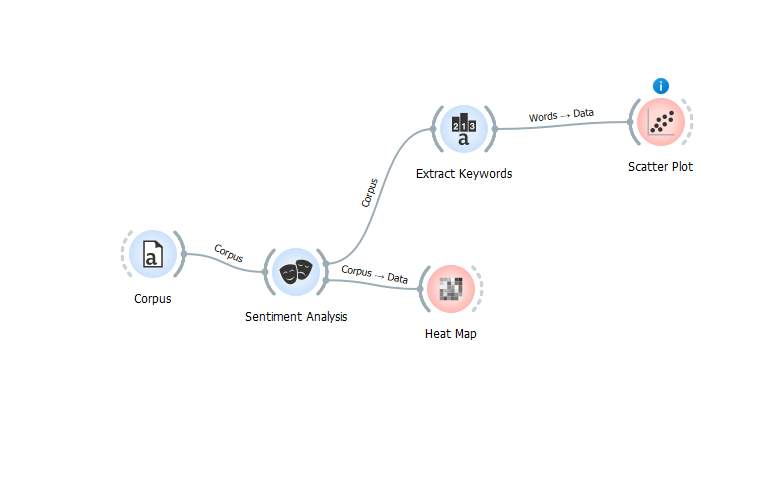
3. Соедините Corpus с Sentiment Analysis. Выберите в последнем режим Vader;
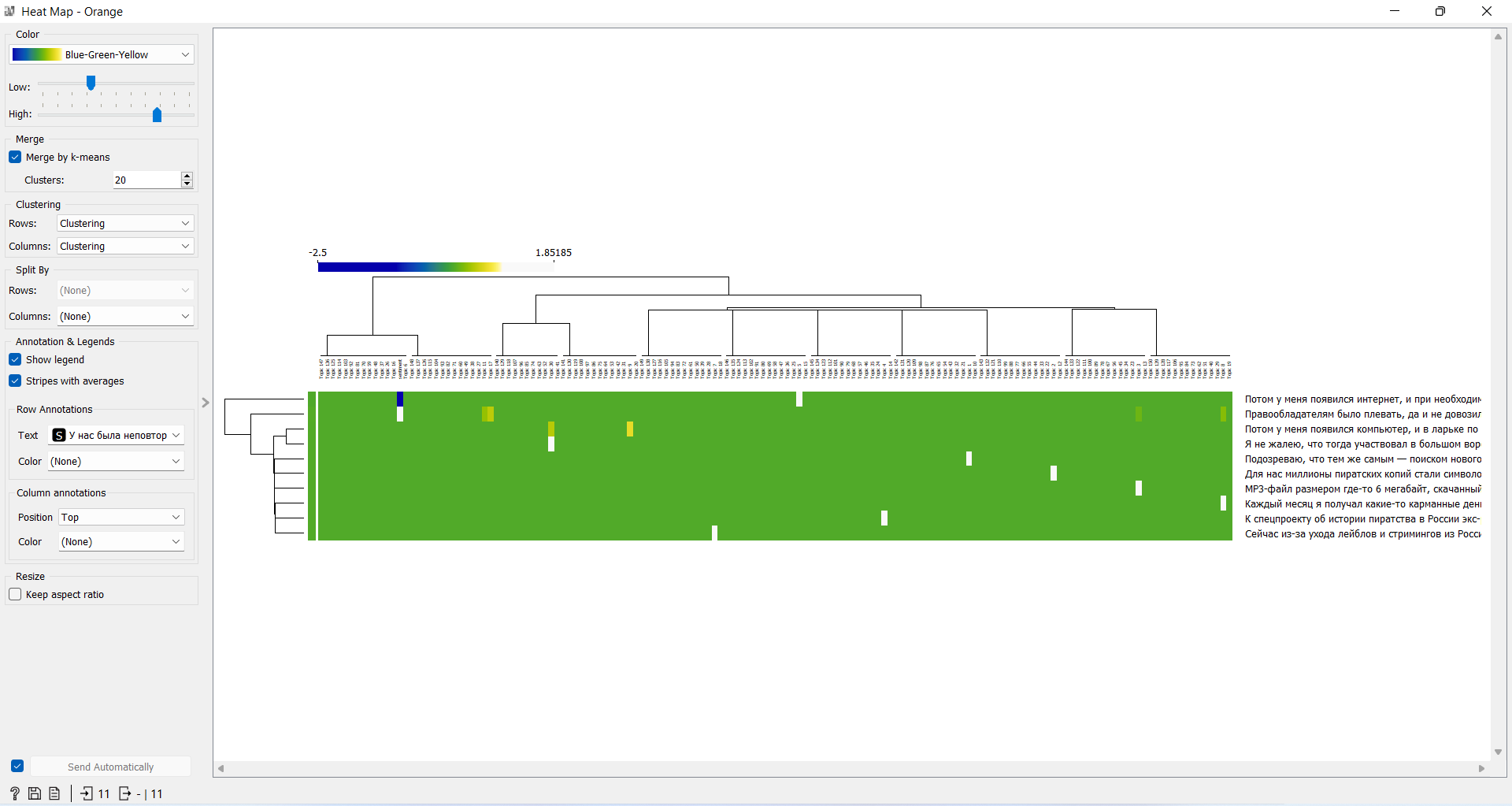
4. Соедините Sentiment Analysis с Heat Map. В разделе кластеризации выберите - clustering, в аннотации - интересующую вас тональность.

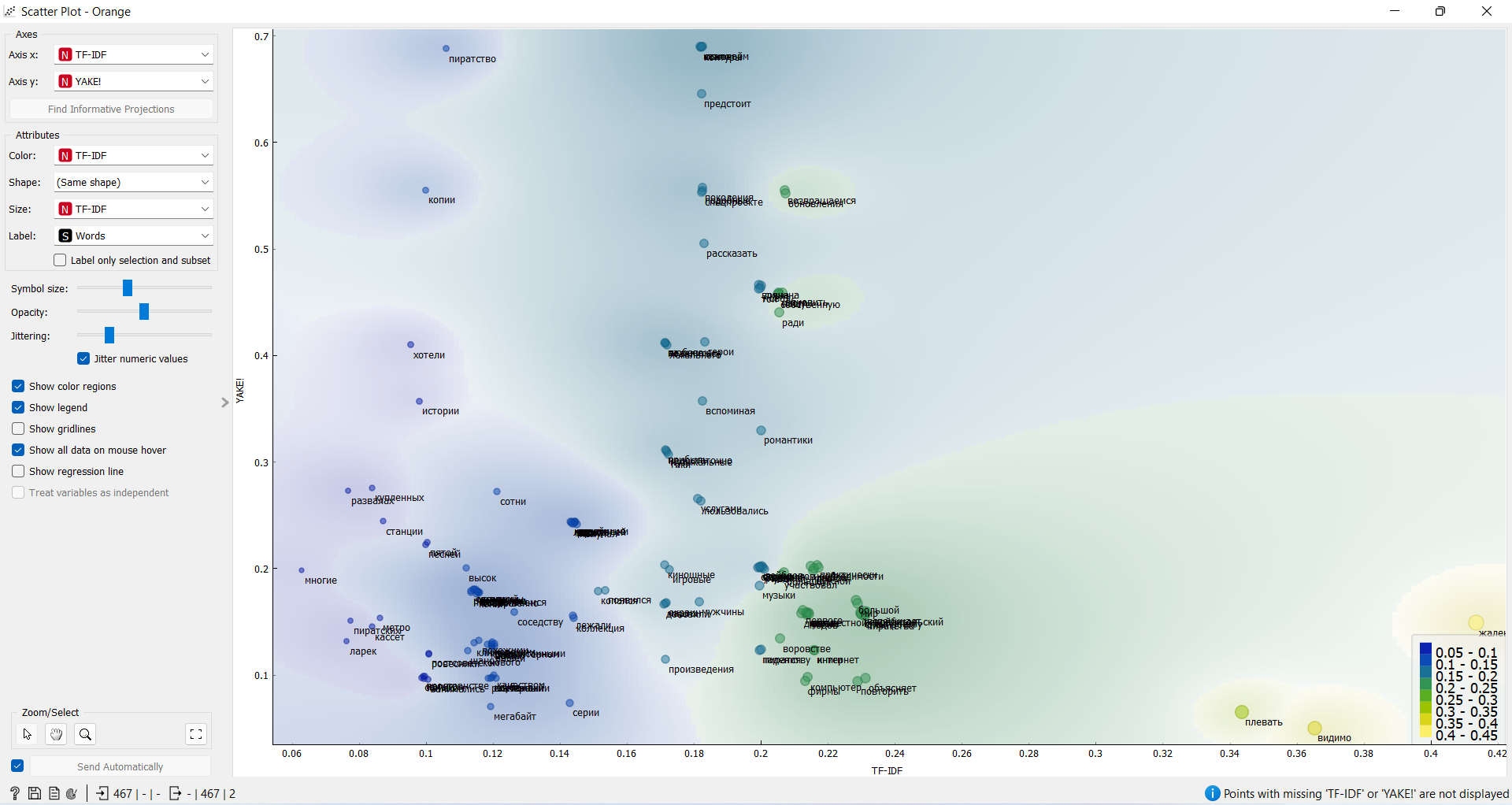
5. Подключите Sentiment Analysis к Extract Keywords. Выберите методы TF-IDF и YAKE! и внизу окна укажите все слова.
6. Подключите к Extract Keywords инструмент Scater Plot. Выставите TF-IDF и YAKE! на осях Х и У. В атрибуте лейбла укажите "words". У вас сгенерируется проекция текста с общими полями слов.
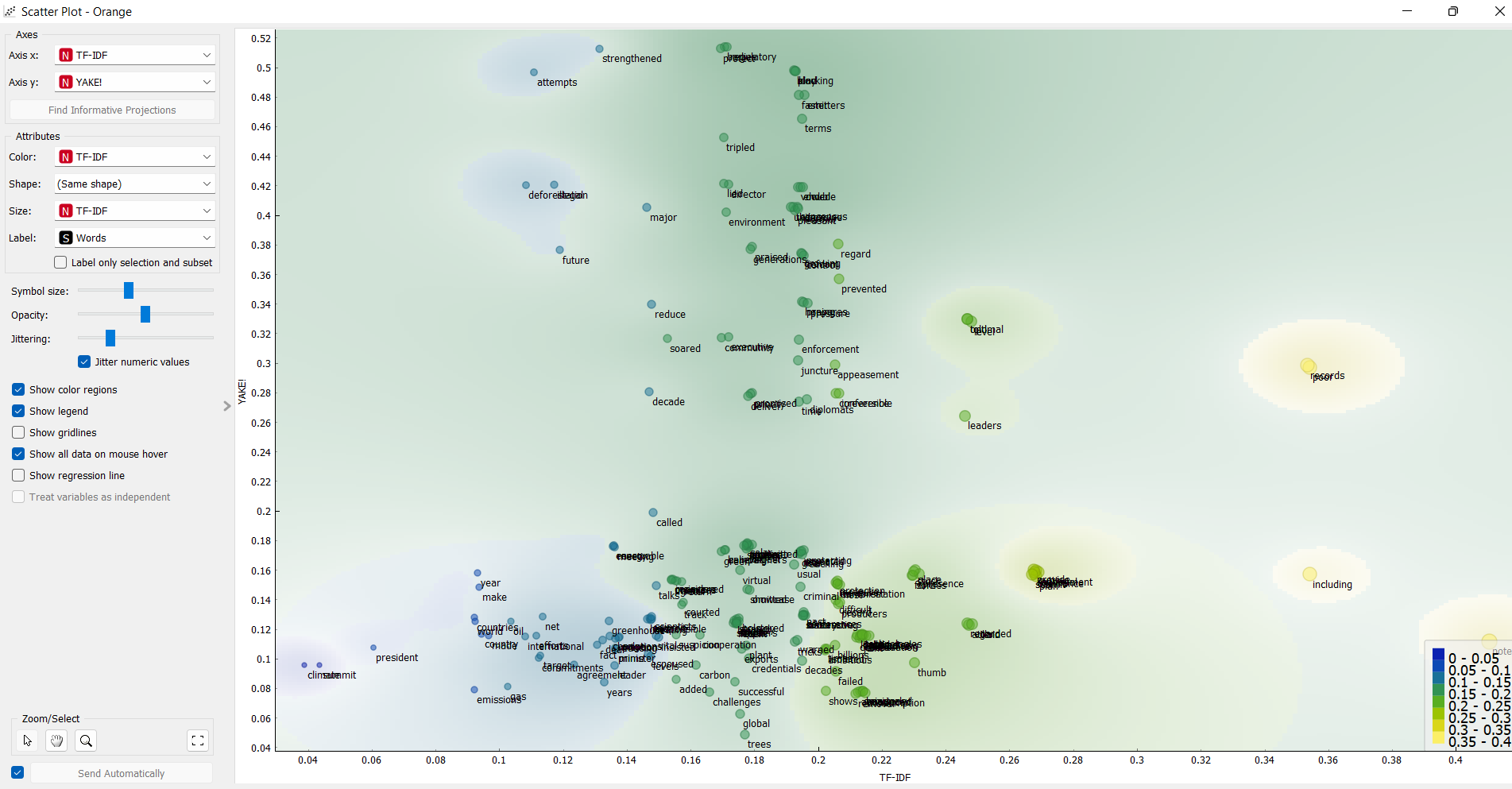
7. На основе данных из пунктов 4 и 6 кратко проанализируйте какая тональность доминирует в тексте и какие слова объединяются в общие группы. Ссылки на выполненное задание принимаются в комментариях к данному посту до 15:00 четверга, 10 ноября.
P.S. Можно использовать русский язык, но тогда связь компонентов будет такой:
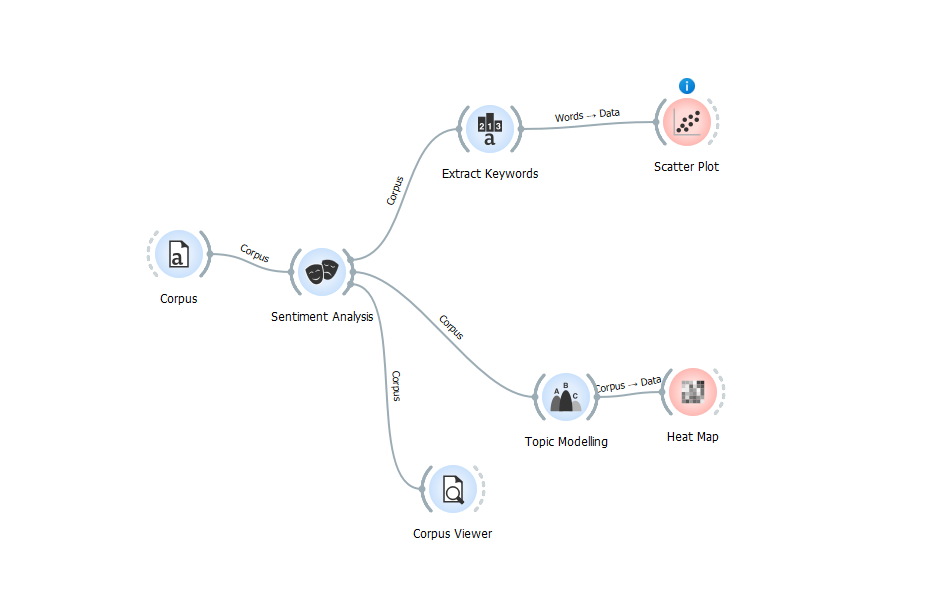
2) В компоненте Sentiment Analysis выбираете мультиязычный компонент и устанавливаете русский язык;
3) Подключаете компонент Corpus Viewer. В нем должны отобразиться все абзацы публикации;
4) Подключаете Sentiment Analysis к компоненту Extract Keywords. В нем выбираете методику term frequency inverse document frequency (важность упоминаемых слов) и модель Yet Another Keyword Extractor. Переключаетесь на русский язык, внизу выбираете опцию учитывать все слова;

Гридасова
ОтветитьУдалитьhttps://ertarrin.blogspot.com/2022/11/5.html
Оценка "отлично"
Удалитьhttps://yanasolais.blogspot.com/2022/11/101-5.html
ОтветитьУдалитьОценка "отлично"
УдалитьСтарцева https://jstartseva.blogspot.com/2022/11/5.html
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://daryamarcova.blogspot.com/2022/11/blog-post.html
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://sabina-musina.blogspot.com/2022/11/26-2022-101-5-sentiment.html
ОтветитьУдалитьОценка "отлично"
Удалитьhttps://victoriakram.blogspot.com/2022/11/5-sentiment.html
ОтветитьУдалитьhttps://shilenbergalexander.blogspot.com/2022/12/5-sentiment.html
ОтветитьУдалитьhttps://mariasmirnova19.blogspot.com/2022/12/guardian-1821-tesla-lvmh.html
ОтветитьУдалить